Why Vision Language Models Matter More Than LLMs for Biotech

Why Automated Image Analysis Has Been Out of Reach for Lean Teams
In early-stage R&D, lean teams couldn't even put automated image analysis on the table. Scientists did what they always do: they found a way to do it manually. Large Vision Models are changing that, and they deserve more attention than they've gotten.
While LLMs have been in the spotlight, specialized vision models and Vision Language Models (VLMs), the newer term for models that combine vision and language capabilities, deserve recognition for their transformative role in advanced image processing, particularly for lean teams working at the pace of real science.
Picture a researcher manually reviewing hundreds of plant images, counting and annotating leaves one by one, not because it's the best use of their time, but because no affordable automated solution exists fast enough to keep up with the experiment. This was the reality for one of our biotech customers.
The Traditional Machine Learning Problem
In organizations with specialized ML teams, a task like image-based leaf detection would typically mean:
- Collecting hundreds of images
- Paying offshore teams to prepare masks for each leaf
- Handing off the training set to ML engineers
- Creating a model architecture and training pipelines
- Waiting for success—or worse, for edge cases to emerge
If successful, this model would be highly tailored to the specific training set it was designed from. This process can take at best 3 months, but often much longer as edge cases are identified. In biotech R&D, by the time a model is ready, the experimentation may have already moved on, rendering the imaging model obsolete.
The dependence on this traditional pipeline meant scientists were often stuck doing manual image analysis, and automated solutions rarely could be developed in time to assist them in the lab.
One Model, Every Task: The Promise of General-Purpose Vision
Back in mid-2024, when large vision models were just starting to be released, the idea that a pretrained model with general vision capabilities could help with imaging tasks was just starting to be realized. My first experimentation with generalized vision models was with Microsoft's Florence-2 LVM.
Florence-2 handles captioning, detection, OCR, and segmentation through a single prompt-based interface. You tell it what task you want, it does it. Florence-2 was trained on a massive dataset of 126 million images with 5.4 billion annotations, spanning every level of visual understanding: from high-level captions down to precise object locations and region descriptions. This breadth is what lets a single small model generalize across so many tasks without task-specific architectures.
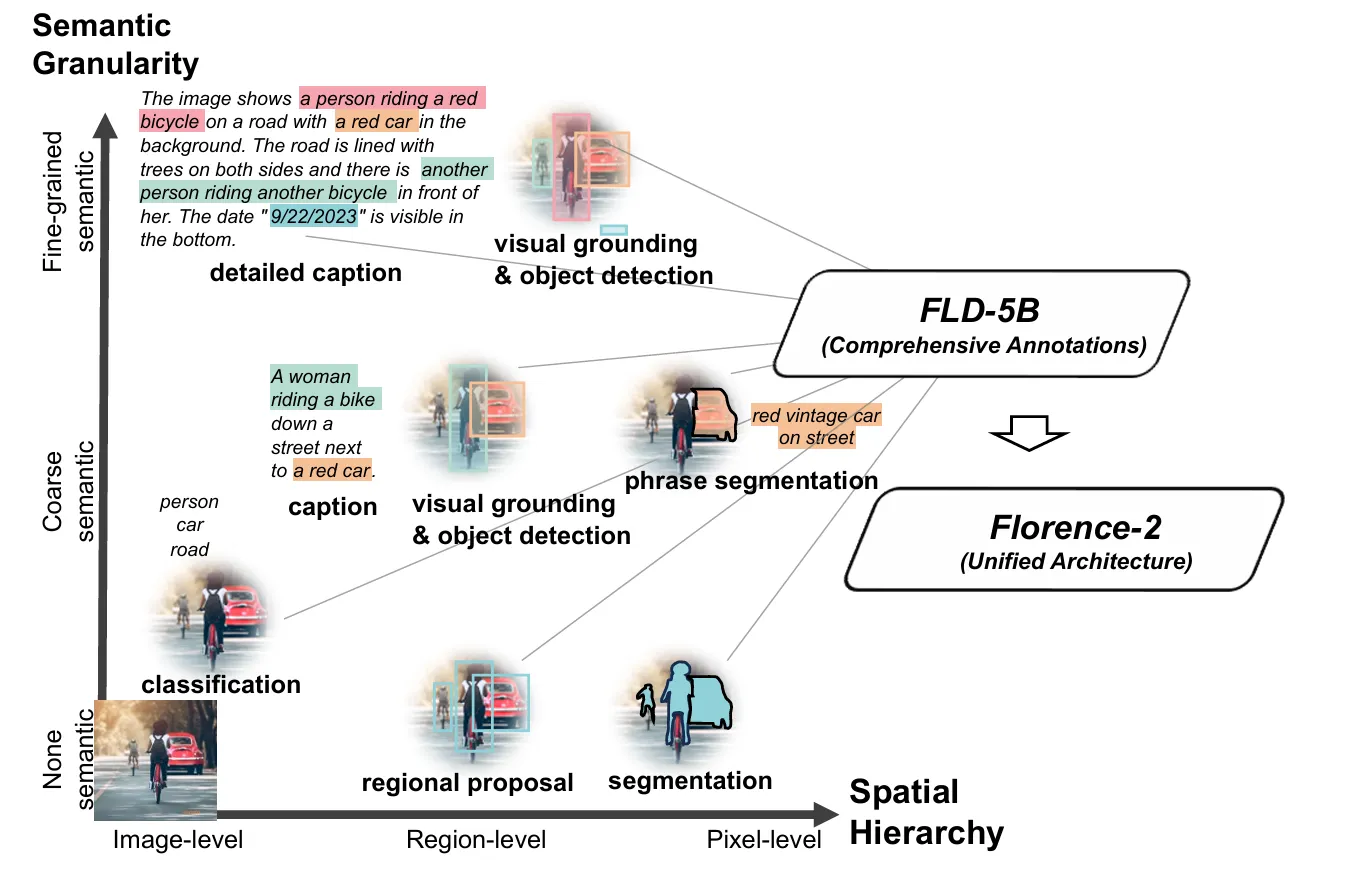
Figure: Florence-2 demonstrates semantic granularity across classification, visual grounding, segmentation, and detailed captioning in a unified architecture.
In practice, this means you can point it at a lab image it has never seen and get useful results without writing a single line of training code.
From Petri Dish to Pipeline: Putting General Vision to Work
This generalized model can be used to localize objects in an image, and in scientific workflows this is a huge enabler when you need to find a petri dish, a leaf, or any other object in general or lab settings.
Once an object is localized, you can pass it downstream for further image processing:
- Count instances across the image
- Perform semantic segmentation
- Prepare training data for more specialized models
- Automate quality control checks
For our biotech customer, this meant going from a researcher manually annotating leaves to an automated pipeline identifying and localizing every leaf in an image, deployed in days, not months. This capability can be readily deployed by lean teams and quickly iterated to meet the rapidly evolving needs of hard tech and biotech organizations. It's a game changer for those who already have an image analysis use case and for those who never considered such automation, having assumed the resources and technology were too difficult to work with.
What We Can Build With You — In Weeks, Not Months
Since mid-2024, the ecosystem has grown significantly. Over 100 open-source vision language models were released, and deployment-ready options like YOLO26 have set new baselines for real-time vision AI. Many multimodal LLMs like GPT-4V, Gemini, and Claude now handle image understanding natively. However, localization (detecting and bounding specific objects) remains a specialized capability of dedicated models, not a standard feature of frontier LLMs. For precise object detection tasks, specialized vision models remain the right choice, and they're now deployable fast enough to keep pace with real-time research needs.
If your team is sitting on an image analysis problem you've shelved because it seemed too resource-intensive or too slow to be worth it, that calculus has changed.
Get It Works can help you:
- Assess your image analysis use case
- Identify the right model approach for your data
- Get something working in your hands fast
- Deploy with FastAPI and Streamlit without large compute infrastructure
Reach out and let's see what's possible for your team. Image automation is no longer reserved for organizations with dedicated ML teams.
Next: Explore how finding the right vendors helps lean teams move fast on hardware and software infrastructure decisions.